Last updated August 11, 2017 at 4:47 pm
Happy World Emoji Day on July 17! Here’s a run down on the world of emojis – the newest additions, the Unicode and encoding ?
In the last version of emoji release, there are 56 new emoji characters (not including gender and skin tone emoji sequences).
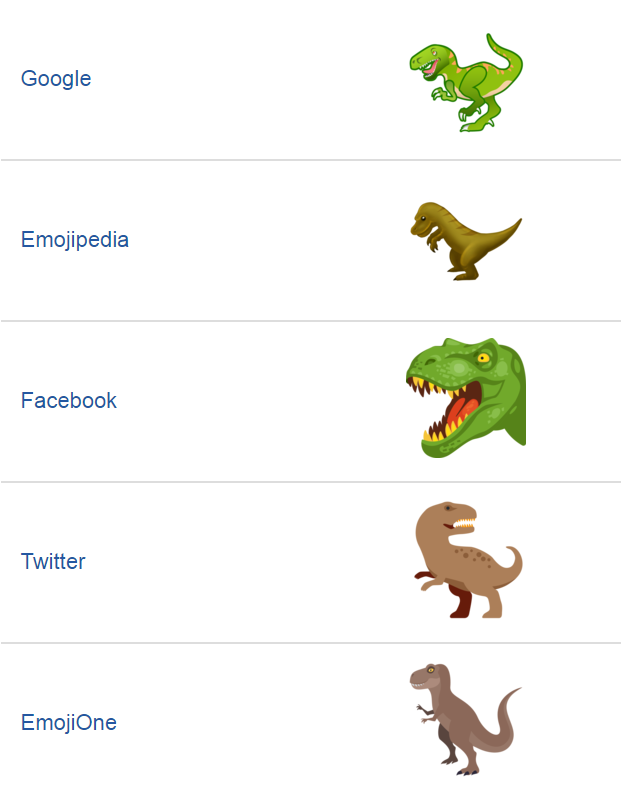
There’s finally TWO DINOSAUR EMOJIS! Not one – two! There’s an adorable bright green sauropod ? and an non-threatening-looking T-rex ? complete with little arms.

And while we’re on the vaguely zoology theme, a zebra, giraffe, hedgehog, and grasshopper have been added. And for the sci-fi fans, there’s a flying saucer emoji!
I’m also incredibly excited by the dumpling and the chopstick emoji because dumplings are (my) life. Other welcome additions are more inclusive, like a gender-neutral child, adult and older adult. There’s also a bunch of fantasy, mythical creatures like a fairy, vampire, merperson, genie, zombie…
By the way, the reason for July 17 is World Emoji Day is that on the iOS version of the Calendar Emoji it is the date displayed.
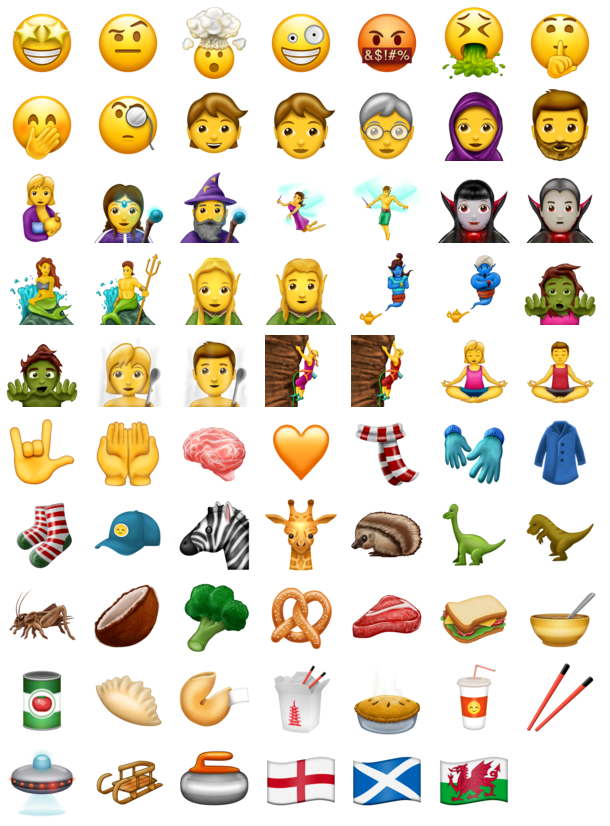
Credit: Emojipedia © 2017
The world of emojis is expressive, colourful and fun. Emojis are more than just cute pictures that we just use to let our emojis do the talking and express our reactions for us. But it’s actually a lot harder than you think to create an emoji. Enter the Unicode.
The Unicode Consortium recently released version 10.0 of the Unicode Standard on 20 June 2017. Unicode 10.0 added 8,518 characters, for a total of 136,690 characters. These additions include 4 new scripts, for a total of 139 scripts, as well as 56 new emoji characters.
Part of this included new emoji code points as part of Emoji Version 5.0. This list was announced in March 2017, but with Unicode 10.0 the code points required are finally sorted out. Now vendors like Apple, Google, Microsoft, Samsung and more can incorporate these code points and support them in upcoming software updates. We can expect these updates to come later in 2017.
But you might be asking, what is Unicode?
According to the Oxford Dictionary definition:
It’s an international encoding standard for use with different languages and scripts, by which each letter, digit, or symbol is assigned a unique numeric value that applies across different platforms and programs.
- Fun fact: a script can encode multiple languages. For example, the Latin script supports English, French, German, Vietnamese, Latin and more.
Every letter in every alphabet is assigned a code point by the Unicode Consortium which is written as “U+” with a number, i.e. U+0041. The U+ means Unicode and the numbers are hexadecimal. Earlier on, before it was standardised, Unicode was based on Western lettering which made it complicated when other characters from languages needed to be encoded. Thus, it was necessary to create an international standard.
Encoding is how code points are stored or represented. They vary in simplicity and efficiency in terms of how the Unicode data is stored. There’s now multiple ways of encoding Unicode; the most commonly used encodings are UTF-8 and UTF-16.
� if you’ve seen this symbol before, it’s because there’s no equivalent for the code point in the encoding you’re using. It’s necessary to use a header in your coding to indicate how the text was encoded.
- If you’ve ever wanted to create your own emoji, you can submit a proposal to the Unicode Emoji subcommittee: http://unicode.org/emoji/selection.html
- This an excellent, in-depth but simple-to-understand blog which explains Unicode: https://betterexplained.com/articles/unicode/
Follow us on Facebook, Twitter and Instagram to get all the latest science.